Support Vector Machine (SVM)
O que é SVM?
O Support Vector Machine (SVM) é um algoritmo de aprendizado de máquina supervisionado usado para classificação e regressão. Ele é particularmente eficaz em problemas de classificação binária, onde o objetivo é separar duas classes distintas em um espaço de características.
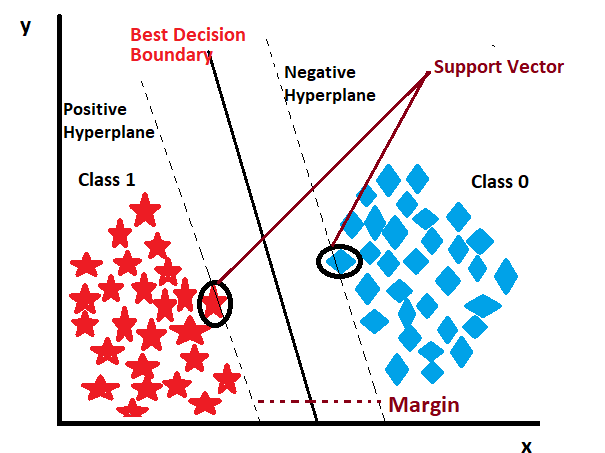
O SVM funciona encontrando o hiperplano que melhor separa as classes em um espaço de alta dimensão. O hiperplano é uma linha (em 2D), um plano (em 3D) ou um espaço de dimensão superior que divide os dados em diferentes classes. O SVM tenta maximizar a margem entre as classes, ou seja, a distância entre o hiperplano e os pontos de dados mais próximos de cada classe, conhecidos como vetores de suporte.
Os vetores de suporte são os pontos de dados mais importantes para a construção do modelo, pois eles definem a posição do hiperplano. O SVM pode ser aplicado a dados lineares e não lineares, utilizando diferentes funções de kernel para transformar os dados em um espaço onde eles possam ser separados linearmente.
Quando aplicar SVM?
- Classificação: Variável dependente categórica.
- Regressão: Variável dependente métrica.
Pode aplicar regressões lineares e não lineares.
Lida bem com bancos de dados de pequeno e médio porte.
Hiperplano
O hiperplano é uma linha (em 2D), um plano (em 3D) ou um espaço de dimensão superior que divide os dados em diferentes classes. O SVM tenta maximizar a margem entre as classes, ou seja, a distância entre o hiperplano e os pontos de dados mais próximos de cada classe, conhecidos como vetores de suporte.
Criterios para avaliação
Matriz de confusão:
- Verdadeiro positivo (VP): O modelo previu corretamente a classe positiva.
- Verdadeiro negativo (VN): O modelo previu corretamente a classe negativa.
- Falso positivo (FP): O modelo previu incorretamente a classe positiva.
- Falso negativo (FN): O modelo previu incorretamente a classe negativa.
Acurácia: Proporção de previsões corretas em relação ao total de previsões. Precisão: Proporção de verdadeiros positivos em relação ao total de previsões positivas. Especificidade: Proporção de verdadeiros negativos em relação ao total de previsões negativas. Sensibilidade: Proporção de verdadeiros positivos em relação ao total de casos positivos reais.
SVM - Classificação não linear
Quando não há separabilidade linear no espaço original das variáveis explicativas (X)
Truque do kernel
O truque do kernel é uma técnica usada no SVM para lidar com dados não linearmente separáveis. Em vez de tentar encontrar um hiperplano em um espaço de alta dimensão, o SVM aplica uma função de kernel para transformar os dados em um espaço de dimensão superior onde eles podem ser separados linearmente.
Busca a similaridade entre os pontos de dados.
Parametrização do kernel não linear
Hiperparâmetros no kernel polinomial:
- degree: grau do polinômio (d)
- coef0: influência dos polinômios de alto grau vs. baixo grau (r)
- gamma: intervalo de influência das observações sobre a fronteira de decisão (γ) ➢ C: penalização atribuída às observações incorretamente classificadas
Hiperparâmetros no kernel RBF:
- gamma: intervalo de influência das observações sobre a fronteira de decisão (γ) ➢ C: penalização atribuída às observações incorretamente classificadas