Rede Neural Recorrente (RNN)
Uma rede neural recorrente (RNN) é uma classe de redes neurais artificiais onde as conexões entre os nós formam um ciclo. Isso permite que a RNN tenha uma memória interna, o que a torna ideal para tarefas de processamento de sequência.
- Recorrente: Realiza a mesma tarefa para todos os elementos de uma sequência, com a saída sendo dependente de cálculos anteriores.
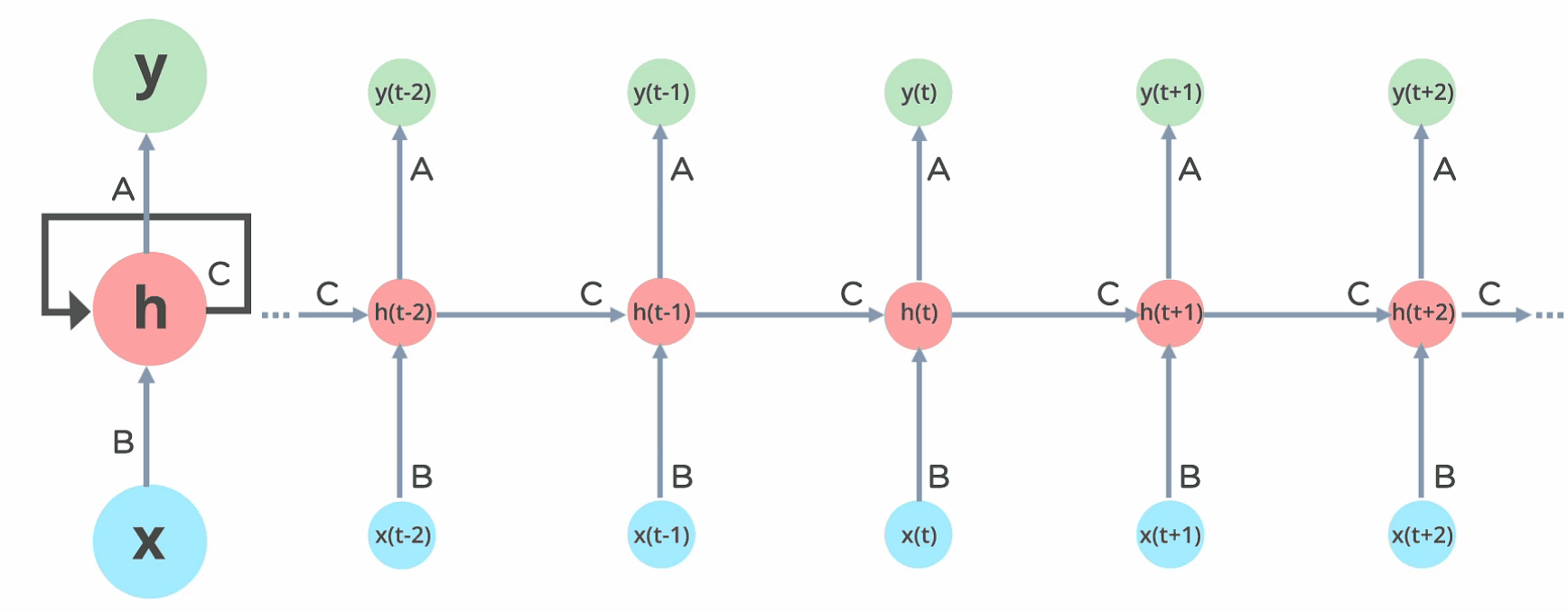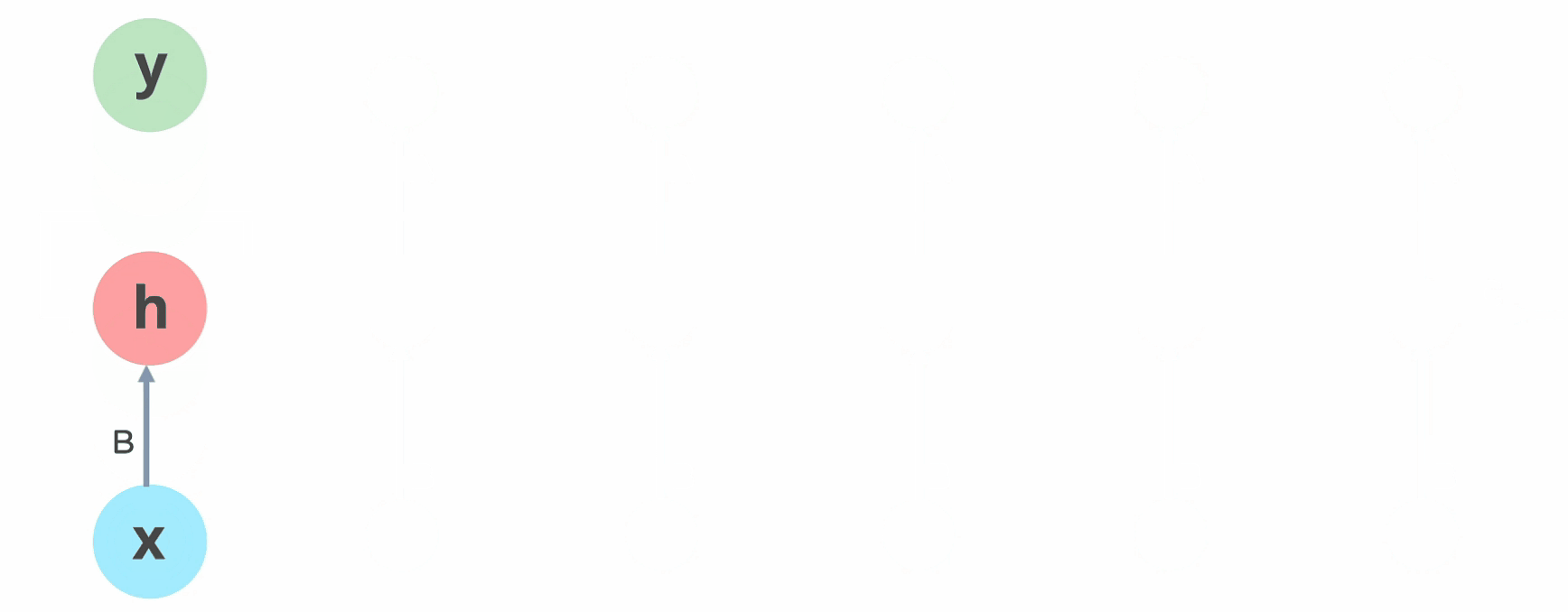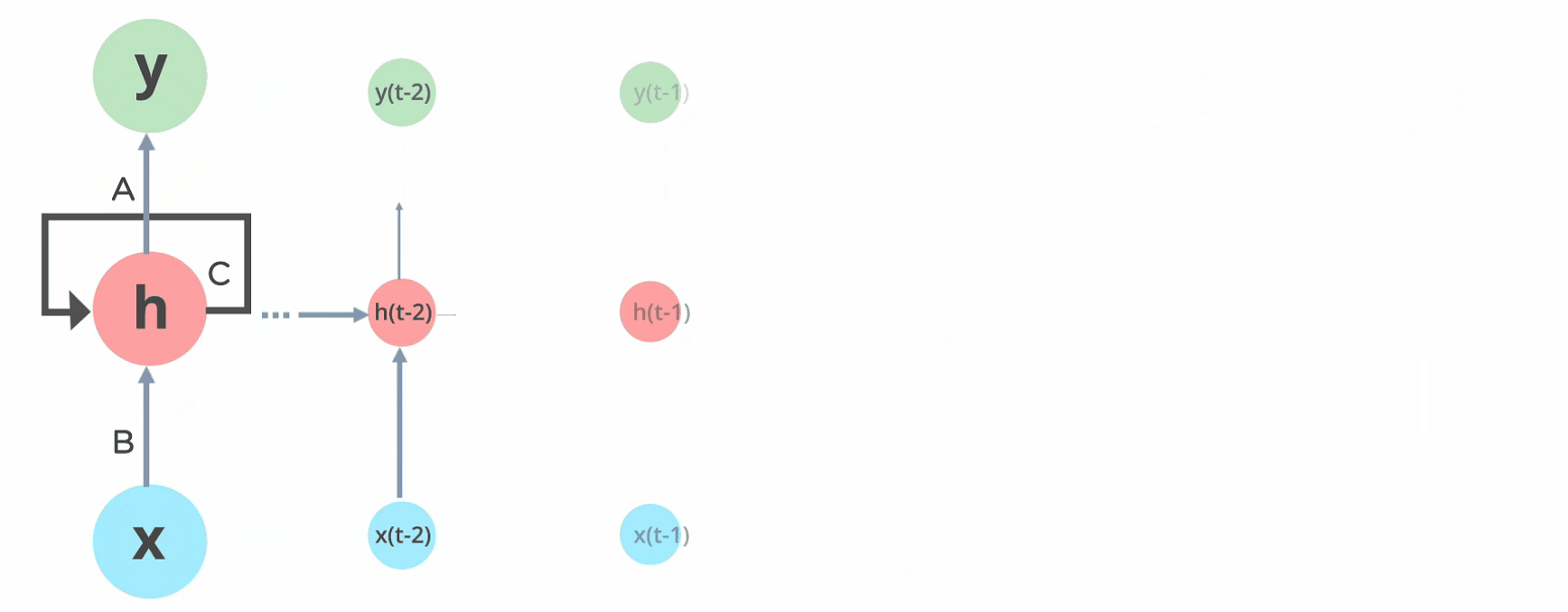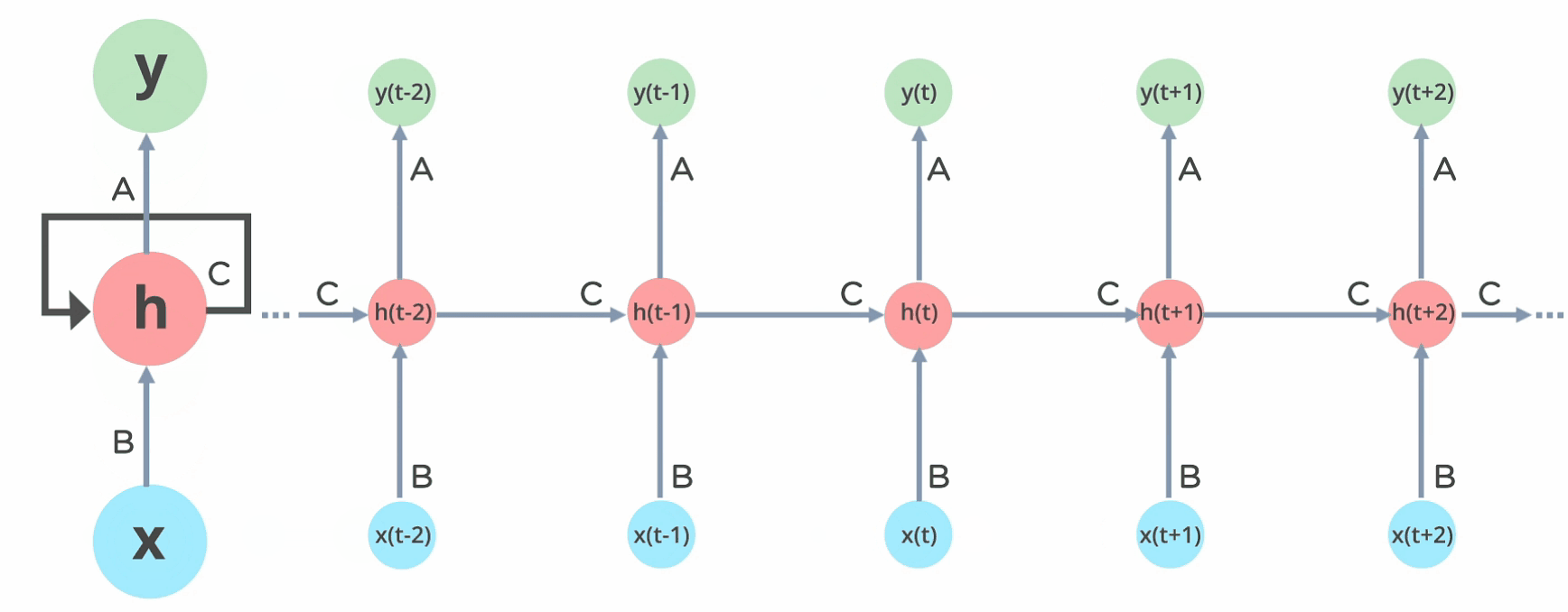
Rede de Elman
A rede de Elman é uma das primeiras redes neurais recorrentes propostas. Ela é composta por uma camada de entrada, uma camada oculta e uma camada de saída. A camada oculta é conectada a si mesma, permitindo que a rede mantenha uma memória interna.
Resultados que os valores da camada escondida estarão multiplicados por valores de pesos elevados a potencias maiores quanto mais antiga a informação for.
Isso é o que chamamos de backpropagation through time (BPTT), que é uma técnica de treinamento de redes neurais recorrentes.
Tudo se afeita aos mesmo tempo!
Backpropagation
O backpropagation é um algoritmo de treinamento para redes neurais artificiais. Ele calcula o gradiente da função de custo em relação aos pesos da rede, permitindo que os pesos sejam ajustados de acordo.
Existem alguns problemas com o backpropagation em redes neurais recorrentes, como o gradiente desaparecendo ou explodindo. Para resolver isso, foram propostas algumas técnicas, como gradient clipping e LSTM.
Backpropagation Truncado
O backpropagation truncado é uma técnica que limita o número de passos de tempo que o gradiente é propagado de volta na rede. Isso ajuda a evitar o problema do gradiente desaparecendo ou explodindo. Porém esta técnica aumenta o custo computacional além de ser uma solução arbitrária.
Clipping de Gradiente
Soluciona o problema do gradiente explodindo, limitando o valor do gradiente. Se o gradiente for maior que um determinado valor, ele é reduzido para esse valor. A direção do gradiente é mantida, mas sua magnitude é limitada.
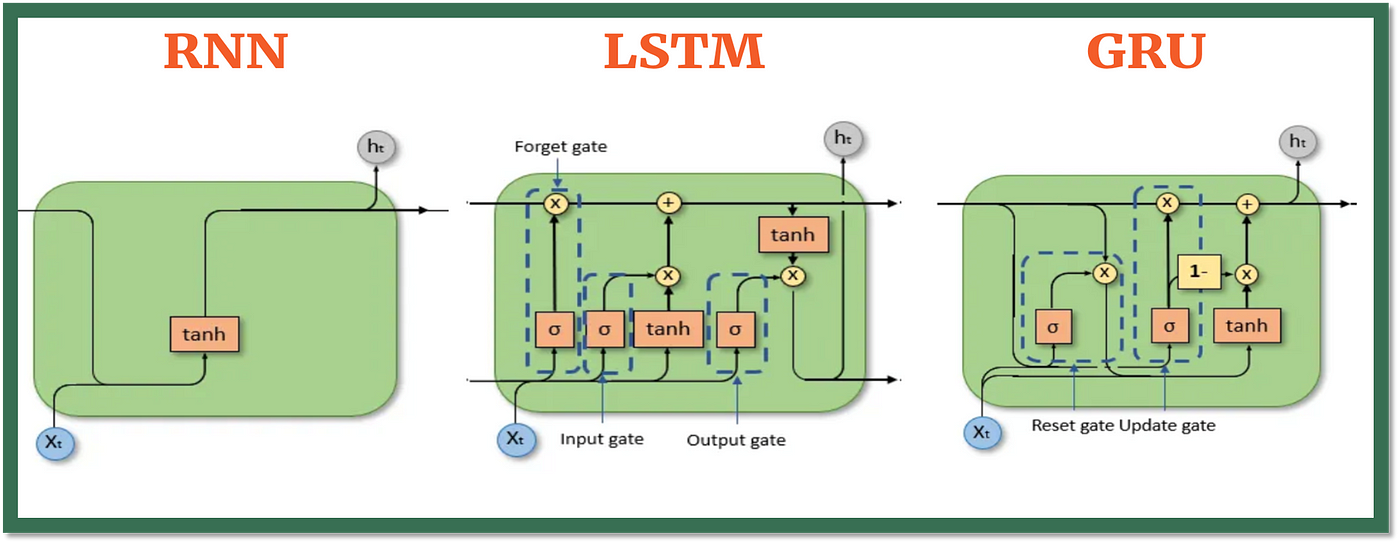
Long Short-Term Memory (LSTM)
O LSTM é uma arquitetura de rede neural recorrente que foi projetada para resolver o problema do gradiente desaparecendo. Ele possui uma célula de memória que pode armazenar informações por longos períodos de tempo, permitindo que a rede mantenha uma memória interna.
- O Estado da celula é o quanto eu aprendi e quero levar para frente.
- Os Portões são responsáveis por decidir o que e quanto entra e o que sai da célula de memória.
Esquecer o que é irrelevante, adicione nova informação e passe adiante a informação atualizada.
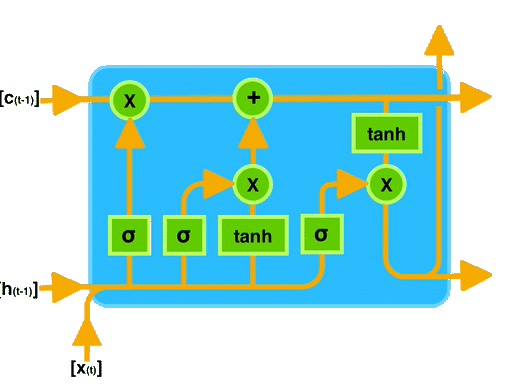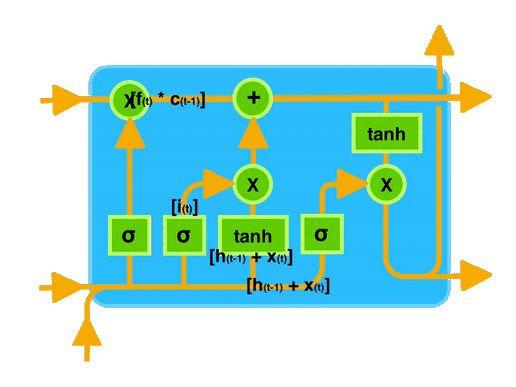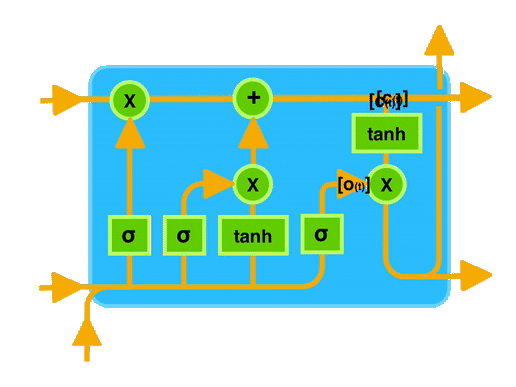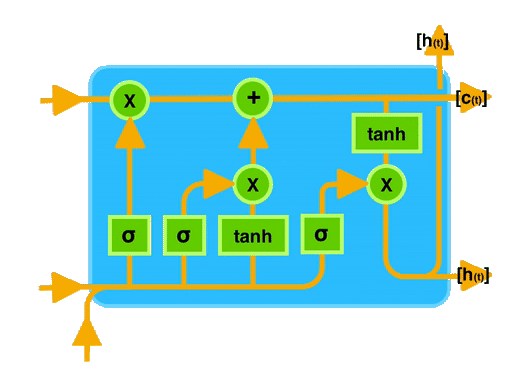
Portões (Gates):
- Forget Gate: Decidir o que esquecer.
- Input Gate: Decidir o que adicionar.
- Output Gate: Decidir o que passar adiante.
Gated Recurrent Unit (GRU)
O GRU é uma variação do LSTM que simplifica a arquitetura, combinando o estado da célula e o estado oculto em um único vetor. Ele possui dois portões, um para atualizar o estado da célula e outro para atualizar o estado oculto. Resolvendo o problema do gradiente desaparecendo.
Baseado em portões:
- Reset Gate: Decidir o quanto esquecer.
- Update Gate: Decidir o quanto adicionar.
Transformadores
Os transformadores são uma arquitetura de rede neural que foi projetada para processar sequências de forma paralela. Eles são compostos por um codificador e um decodificador, que são compostos por várias camadas de atenção.
-
Maior parte de PLN era feito com RNN,
-
Attention is all you need!
-
Codificador: Processa a sequência de entrada e gera uma representação intermediária.
-
Decodificador: Gera a sequência de saída com base na representação intermediária gerada pelo codificador.
-
O que é mais rápido? Ler o livro inteiro ou procurar no índice?
-
Vetor de contexto - Guarda a posição dentro da sequência.
-
Solução: Passar todos estados ocultos.