Big Data
A cada dois anos o numero de dados gerados no mundo dobra. A quantidade de dados gerados em 2020 foi de 64 zettabytes. A previsão é que em 2025 a quantidade de dados gerados seja de 181 zettabytes. A solução para lidar com volumes cada vez maior de dados é o Big Data.
Os 5 Vs do Big Data
- Volume: Refere-se a quantidade massiva de dados gerados.
- Velocidade: Refere-se a rapidez com que os dados são gerados.
- Variedade: Refere-se a diversidade de fontes de dados (dados estruturados, não estruturados e semiestruturados).
- Veracidade: Refere-se a confiabilidade e qualidade dos dados.
- Valor: Refere-se a capacidade de transformar os dados em informações úteis.
Os 5 Vs do Big Data se relacionam entre si. QUando se fala em big data normalmente falamos em ecossistema. O ecossistema de big data é composto por diversas ferramentas e tecnologias que permitem o armazenamento, processamento e análise de grandes volumes de dados.
Muitas empresas utilizam datalake para armazenar e processar grandes volumes de dados. O datalake é um repositório centralizado de dados que armazena todos os tipos de dados em sua forma bruta.
Ferramentas de Big Data
- Hadoop
- Spark
Ambas ferramentas são Frameworks de processamento de dados em larga escala para lidar com os desafios do 5Vs do Big Data. São projetados em ambientes distribuídos onde clusters são utilizados para processar grandes volumes de dados (dividir para conquistar).

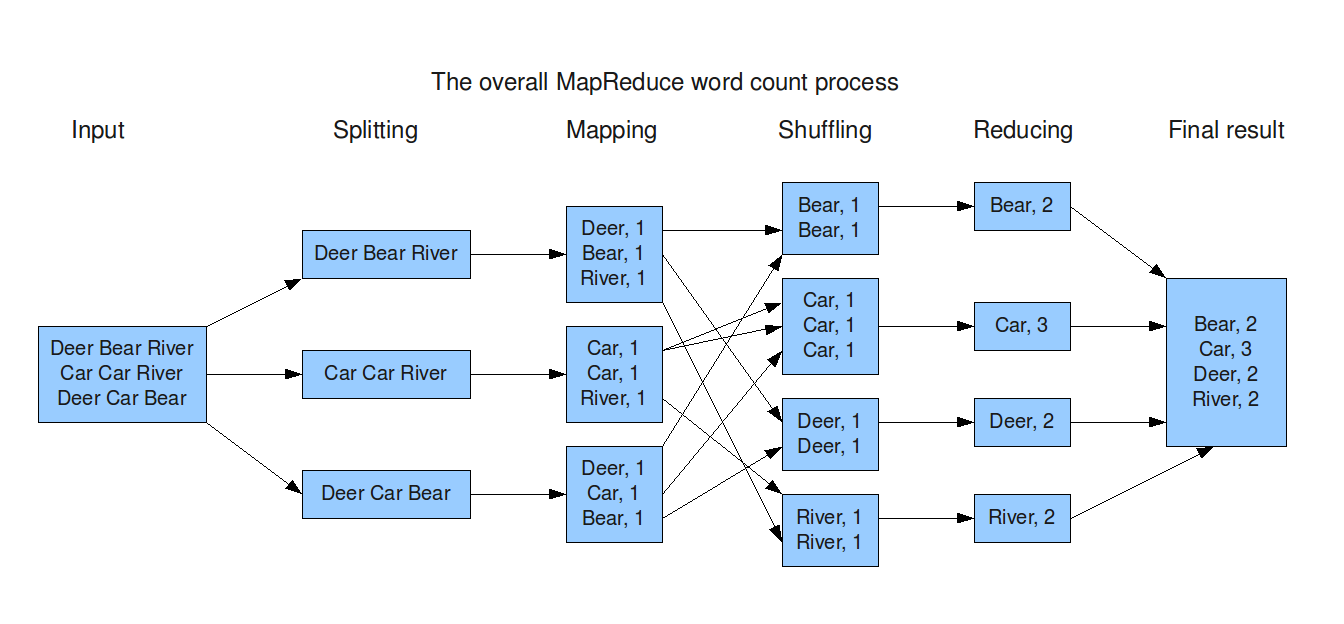
Hadoop MapReduce
- Armazenamento distribuído: HDFS (Hadoop Distributed File System)
- Processamento distribuído: MapReduce - Facilita o processamento paralelo, dividindo tarefas em nós do cluster.
- Escalabilidade horizontal: Adicionar mais máquinas ao cluster para aumentar a capacidade de processamento.
Spark


- Processamento de dados em mem�ória: O Spark é mais rápido que o Hadoop, pois armazena os dados em memória, reduzindo o tempo de leitura e escrita em disco.
- Suporte a múltiplos tipos de dados: O Spark suporta dados estruturados, não estruturados e semiestruturados.
- Pipeline de dados complexos: O Spark permite a criação de pipelines de dados complexos, com suporte a diversas operações de transformação e análise de dados.
- Machine Learning Integrado: O Spark possui uma biblioteca de Machine Learning integrada (MLlib), permitindo a criação de modelos de Machine Learning em larga escala.
- Streaming de dados: O Spark possui suporte a streaming de dados em tempo real, permitindo a análise de dados em tempo real.
DAG (Directed Acyclic Graph)
DAG (Directed Acyclic Graph): Representação grafica das operações que serão executadas.
Características:
- Direcionado: As arestas tem uma direção. Indica a ordem de execução das operações.
- Acíclico: Não possui ciclos. Uma vez que uma operação é executada, ela não será executada novamente.
Função: O DAG permite que o Spark otimize o processamento dos dados, reduzindo o tempo de execução.
RDD (Resilient Distributed Dataset)
RDD (Resilient Distributed Dataset): Estrutura de dados do Spark que permite o processamento distribuído dos dados, representando uma coleção de objetos imutáveis que podem ser processados em paralelo.
Características:
- Resiliente: Capacidade de recuperar os dados em caso de falha.
- Distribuído: Os dados são distribuídos entre os nós do cluster.
- Imutável: Os dados não podem ser alterados. Novas transformações geram novos RDDs.
Operações:
- Transformações: Operações que geram um novo RDD (ex. map, filter).
- Ações: Operações que geram um resultado (ex. count, collect).
Estrategias de Armazenamento de Dados
Compressão de dados
Compressão de Dados (Ex. ORC, Parquet, Avro...);
Redução de tamanho -> Mais rápido para carregar e processar -> mais barato processar e armazenar
CSV para Parquet:
- até 87% de redução de tamanho
- até 34% mais rápido para carregar
- até 99% de redução de custo
Particionamento de Dados
Particionamento de Dados (Ex. Particionamento por Data, Particionamento por Chave...);
Spark na pratica
- UI de gerecimento: http://localhost:4040
df = spark.read.csv(f"{WORKDIR}/_datasets/2016.csv", header=True, inferSchema=True)
print(df) # não carrega os dados pois não estão no kenel estão no cluster
df.show() # mostra os dados do cluster, em uma base de dados grande não é recomendado, pode demorar muito e travar o cluster
df.printSchema() # mostra o schema da base de dados
- inferSchema: tenta inferir o tipo de dado da coluna
Operações de Transformação só são executadas quando uma Ação é chamada, exemplo, show(), collect(), count().
Consigo ver na UI os detalhes de processamento de cada job, acompanhar o tempo de execução, o tempo de execução de cada job, o tempo de execução de cada tarefa, o tempo de execução de cada estágio, o tempo de execução de cada operação, visualização da DAG e etc.
Posso pegar somente uma parte dos dados para visualizar, por exemplo, 1% dos registros:
pequena_amostra = df.sample(fraction=0.01)
Com isso, consigo fazer inferências sobre a base de dados sem precisar carregar todos os dados.
O Spark oferece diversas operações de transformação e ação para manipular e analisar os dados.
import pyspark.sql.functions as F
# Extraindo o ano da variável FL_DATE
df = df.withColumn("ano", F.year(df["FL_DATE"]))
# Lógica: contagem quando cada linha da coluna é um valor nulo
df.select([F.count(F.when(F.isnull(c), c)).alias(c) for c in df.columns]).show(
vertical=True
)
# Agrupando por mes e agregando pela média do atraso na chegada
df.groupby("mes").agg(F.avg("ARR_DELAY").alias("media_atraso_chegada")).show()
# Ente outros
Consigo transformar o dataframe spark em um dataframe pandas, posso reduzir o tamanho fazendo transformações no spark e depois passar para o pandas para fazer análises mais detalhadas e gráficos.
df_reduzido_pandas = df_reduzido.toPandas()
ax = sns.barplot(
df_reduzido_pandas.sort_values(by="y", ascending=False),
x="x",
y="y",
color="#8e44ad"
)
Após finalizar:
# Retirando o dataframe spark da memória e do disco
df.unpersist()
# Finalizando a aplicação Spark
spark.stop()